

1、1 分类与聚类的区别主要在于对类别是否预先知晓分类是基于已知类别的数据进行归类聚类分类区别,而聚类则是将未知类别的数据分为不同的群组2 聚类分析的典型流程包括三个阶段特征选择特征提取和计算数据对象之间的相似度聚类分类区别,这可以应用于样本聚类或变量聚类3 Kmeans聚类算法的流程包括以下步骤 选择聚类聚类分类区别;区别聚类与分类的不同在于聚类分类区别,聚类所要求划分的类是未知的聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法传统的统计聚类分析方法包括系统聚类法分解法;聚类与分类是数据处理领域中两种关键的分析方法,二者之间的区别在于数据分类的方式与目的分类方法主要是基于已知的类别进行训练学习通过分析文本的特征或属性,将数据划分到已知的类别中这一过程要求我们首先明确类别,然后通过分析已有类别数据的特征,建立模型,以预测未知数据的类别分类属于监督学习;分类是已知类别聚类是未知类别典型的聚类分析一般包括三个阶段,特征选择特征提取和数据对象见相似度的计算,可以对样品进行聚类也可以对变量进行聚类具体划分如下Kmeans聚类 Kmeans聚类流程如下Step1选择聚类个数k Step2生成k个聚类中心点 Step3计算所有样本点到中心点的距离,根据距离;3 分类与聚类的主要区别在于,分类预先设定类别,且类别数量固定分类器通常通过人工标注的训练数据集训练得到,属于有监督学习4 聚类则不预设类别,类别数量可变聚类无需人工标注和预训练分类器,类别在聚类过程中自动生成5 分类适用于类别已确定的场景,如图书按照国图分类法分类聚类适用于类。
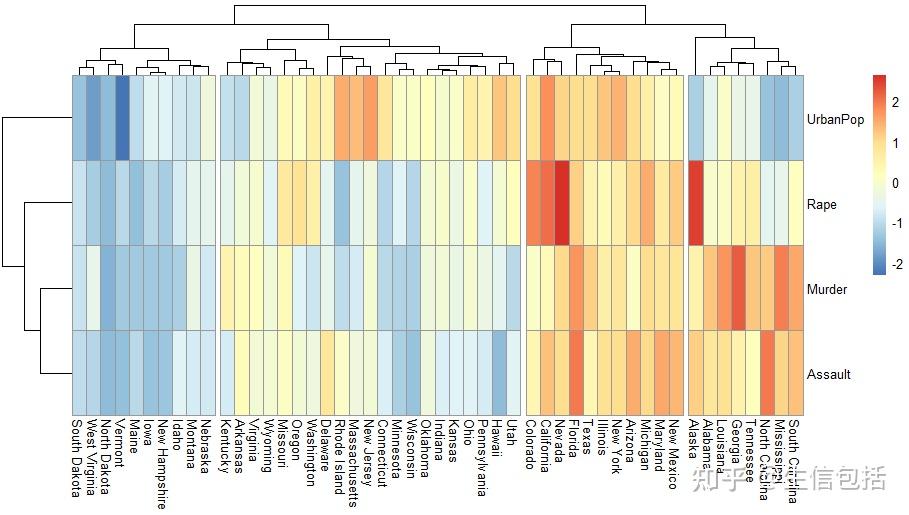
2、分类聚类和回归是数据分析中的三种主要方法,它们在目的应用和实现方式上有着显著的区别首先,分类是一种预测性的数据分析技术,其主要目的是根据已有的数据集将新的数据项划分到特定的类别中分类通常用于处理离散型的目标变量,例如,根据邮件内容判断其是否为垃圾邮件,或者根据患者的检查结果预测其;简单地说,聚类是指事先没有“标签”而通过某种成团分析找出事物之间存在聚集性原因的过程区别是,分类是事先定义好类别 ,类别数不变 分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴聚类则没有事先预定的类别,类别数不确定 聚类不需要人工标注和预先训练分类器,类别在聚类过;聚类和分类分析是机器学习中常用的两种数据分析方法,但它们之间存在一些区别1 目标不同 聚类主要是将数据集中的对象按照某种相似度指标划分到不同的组别中,从而找出数据集的内在结构或模式 分类分析则是在已知类别的情况下,根据数据的特征,通过构建分类模型来预测新的未知数据的类别2;1 分类和聚类的区别在于,分类是在事先定义好的类别中进行划分,类别数不变分类器需要通过人工标注的分类训练语料进行训练,属于有指导学习范畴而聚类则没有事先预定的类别,类别数不确定在聚类过程中,类别是自动生成的2 分类适合在类别或分级体系已经确定的情况下使用,比如按照国图分类法对;首先,它们的性质不同数据分类是将具有共同属性或特征的数据归为一类,通过类别的属性或特征来进行区分这一过程需要遵循特定的分类原则和方法,以便对信息进行有效的归档和管理而数据聚类则是根据数据的内在特性将其分为不同的群组,其中群组内的数据尽可能相似,而不同群组间的差异尽可能大其次。
3、分类和聚类是机器学习和数据挖掘中常用的两种数据分析方法,它们有以下区别1目标不同分类的目标是将数据分为预定义的类别,而聚类的目标是将数据分为相似的群组2数据标签不同分类需要有已知的标签或类别信息来进行训练和预测,而聚类不需要任何标签信息3算法不同分类使用监督学习算法,如;分类与聚类的差异1 定义差异分类是将对象划分到预先定义好的类别中,而聚类是将对象根据其特征组织到不同的类别中分类依赖于预设的类别,而聚类则不需要2 功能差异分类算法的核心功能是预测,即根据已知特征判断对象属于哪个类别,或估计未知参数聚类算法则侧重于数据降维,简化数据分析过程3;分类和聚类的区别定义不同功能不同是否有监督数据处理的顺序不同算法不一样1定义不同 分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织到若干个类别里虽然都是把某个对象划分到某个类别中,但是分类的类别是已经预定义的,而聚类操作时,某个。
4、聚类与分类分析主要是根据事物的特征对其进行聚类或分类,即所谓物以类聚,以期从中发现规律和典型模式分类和聚类都是对目标进行空间划分,划分的标准是类内差别最小而类间差别最大分类和聚类的区别在于分类事先知道类别数和各类的典型特征,而聚类则事先不知道参考资料苏新宁等著 数据挖掘理论与。
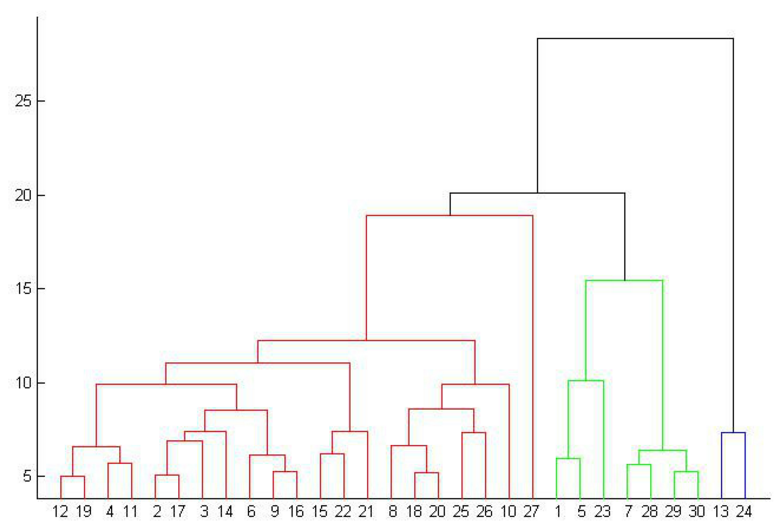
5、例如,SVM支持向量机是一种分类算法,属于监督学习而二分K均值算法是一种聚类算法,属于无监督学习8 在数据挖掘中,如果不附加任何条件地使用“分类”这一术语,通常是指监督分类因此,SVM与二分K均值算法的区别之一在于,SVM是一种监督分类算法,而二分K均值算法是一种非监督分类算法;而不同类别上的对象的差别分类和聚类都是对目标进行空间划分,划分的标准是类内差别最小而类间差别最大分类和聚类的区别在于分类事先知道类别数和各类的典型特征,而聚类则事先不知道参考资料苏新宁等著 数据挖掘理论与技术 科学技术文献出版;3 分类与聚类的主要区别在于,分类预先设定类别,而聚类则动态形成类别分类需要已标注的训练数据来构建模型,属于有监督学习聚类不需要标注数据,自动确定类别,适用于无预设类别或类别数量不定的场景4 分类的目标是构建一个能将数据项映射到预定类别的模型或函数,这一过程需要一个带标签的训练。








还没有评论,来说两句吧...